python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
등분산성(Homoscedasticity)은 여러 집단의 분산이 동일하다는 가정으로, 많은 통계 검정의 전제 조건이다. 등분산 검정(Test for Homogeneity of Variance)은 이 가정이 타당한지 확인하는 과정이다. 정규성 검정과 마찬가지로, 등분산성 가정이 위배되면 t-검정이나 ANOVA의 결과가 부정확해질 수 있다. 이 장에서는 시각적 방법과 통계적 검정을 통해 등분산성을 평가하고, 등분산성이 위배될 때의 대응 전략을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom scipy import stats# 데이터 로드df = sns.load_dataset("penguins").dropna()print("데이터 크기:", df.shape)print("\n그룹 변수:")print(df.select_dtypes(include=['object', 'category']).columns.tolist())print("\n연속형 변수:")print(df.select_dtypes(include=[np.number]).columns.tolist())
데이터 크기: (333, 7)
그룹 변수:
['species', 'island', 'sex']
연속형 변수:
['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
13.1 등분산성의 개념
등분산성(Homoscedasticity)은 여러 집단 또는 조건에서 종속 변수의 분산이 동일하다는 가정이다. 수학적으로는 다음과 같이 표현한다.
# 종별 체중 분산 계산print("=== 종별 체중 분산 ===")variances = df.groupby("species")["body_mass_g"].var()print(variances)print(f"\n최대 분산: {variances.max():.2f}")print(f"최소 분산: {variances.min():.2f}")print(f"분산 비율: {variances.max() / variances.min():.2f}:1")
=== 종별 체중 분산 ===
species
Adelie 210332.427964
Chinstrap 147713.454785
Gentoo 251478.332859
Name: body_mass_g, dtype: float64
최대 분산: 251478.33
최소 분산: 147713.45
분산 비율: 1.70:1
일반적으로 최대 분산이 최소 분산의 2배 이상이면 등분산성을 의심해야 한다.
13.2 등분산성 검정의 필요성
등분산성 가정은 여러 통계 기법의 전제 조건이다.
통계 기법별 등분산성 필요 여부
분석 기법
등분산 필요
중요도
비고
Student t-test
필요
높음
등분산 가정 하에 설계됨
ANOVA
필요
매우 높음
F-통계량이 등분산 가정
선형 회귀 (잔차)
필요
매우 높음
이분산성이 계수 추정 왜곡
Welch t-test
불필요
-
이분산 허용
Welch ANOVA
불필요
-
이분산 허용
비모수 검정
불필요
-
분포 가정 없음
부트스트랩
불필요
-
재표본추출 기반
중요한 사실
정규성보다 등분산성 위반이 더 심각한 경우가 많다. 특히 표본 크기가 집단 간 불균형할 때 이분산성은 1종 오류율을 크게 증가시킨다.
13.3 등분산성 검정 시점
등분산성 검정은 다음 시점에 수행한다.
검정 시점
집단 간 평균 비교 전: t-검정이나 ANOVA 수행 전 필수 확인
ANOVA 적용 전: 다집단 비교 시 반드시 검정
회귀 분석의 잔차 진단: 예측값에 따른 잔차 분산 균일성 확인
반복측정 데이터: 시간이나 조건에 따른 분산 변화 확인
분석 흐름
데이터 로드
↓
정규성 검정 (각 그룹)
↓
등분산성 검정 ← 현재 장
↓
├─ 등분산 O → Student t-test / ANOVA
└─ 등분산 X → Welch t-test / Welch ANOVA / 비모수 검정
13.4 시각적 등분산성 점검
통계적 검정 전에 시각적으로 등분산성을 확인하는 것이 중요하다.
13.4.1 박스플롯
박스플롯은 집단 간 분산의 차이를 시각적으로 비교하는 가장 간단한 방법이다.
예제: 박스플롯으로 분산 비교
# 종별 체중 박스플롯fig, axes = plt.subplots(1, 2, figsize=(14, 5))# 박스플롯sns.boxplot(x="species", y="body_mass_g", data=df, ax=axes[0])axes[0].set_title("Body Mass by Species")axes[0].set_xlabel("Species")axes[0].set_ylabel("Body Mass (g)")# 바이올린 플롯 (분포 형태까지 확인)sns.violinplot(x="species", y="body_mass_g", data=df, ax=axes[1])axes[1].set_title("Body Mass Distribution by Species")axes[1].set_xlabel("Species")axes[1].set_ylabel("Body Mass (g)")plt.tight_layout()plt.show()# 집단별 통계량print("\n=== 종별 체중 통계량 ===")summary = df.groupby("species")["body_mass_g"].agg(['mean', 'std', 'var', 'count'])print(summary)
=== 종별 체중 통계량 ===
mean std var count
species
Adelie 3706.164384 458.620135 210332.427964 146
Chinstrap 3733.088235 384.335081 147713.454785 68
Gentoo 5092.436975 501.476154 251478.332859 119
박스플롯 관찰 포인트
박스 높이: IQR(사분위수 범위)을 나타내며, 집단 간 유사해야 함
수염(whisker) 길이: 데이터의 전체 퍼짐 정도, 집단 간 비슷해야 함
이상치 개수: 집단 간 이상치 비율이 크게 다르면 이분산 의심
13.4.2 분산 비교 히스토그램
집단별 분포를 겹쳐서 확인하면 퍼짐의 차이를 직접 비교할 수 있다.
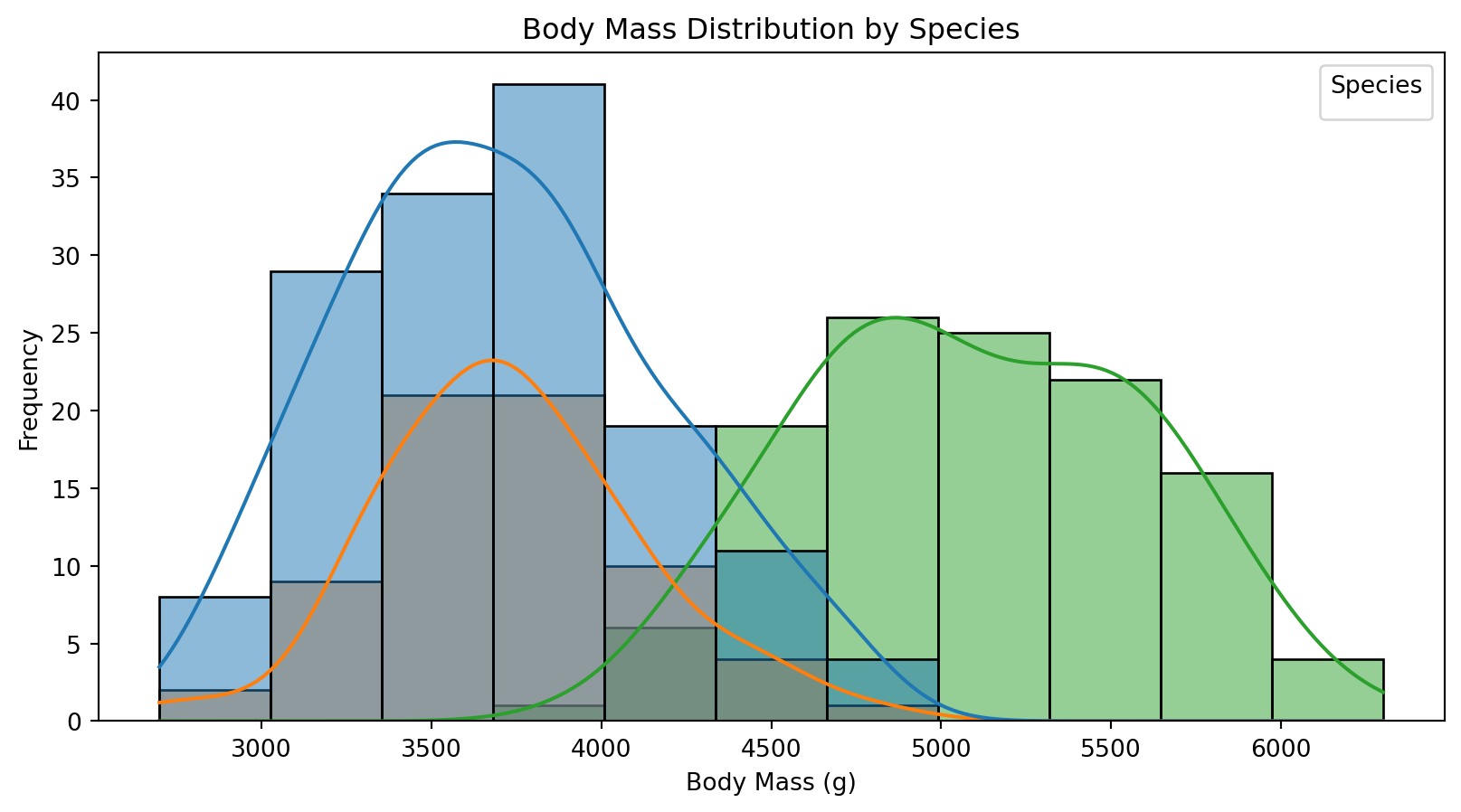
예제: 히스토그램으로 분포 비교
# 종별 체중 분포plt.figure(figsize=(10, 5))sns.histplot(data=df, x="body_mass_g", hue="species", kde=True, alpha=0.5)plt.title("Body Mass Distribution by Species")plt.xlabel("Body Mass (g)")plt.ylabel("Frequency")plt.legend(title="Species")plt.show()
# center 파라미터로 평균 vs 중앙값 선택 가능# center='mean': 평균 기반 (기본값)# center='median': 중앙값 기반 (Brown-Forsythe)# center='trimmed': 절사평균 기반stat_median, p_median = levene(*groups, center='median')print(f"\nLevene (중앙값 기반, Brown-Forsythe): p = {p_median:.4f}")
Levene (중앙값 기반, Brown-Forsythe): p = 0.0064
13.5.3 Bartlett 검정
Bartlett 검정은 로그 우도비를 사용하며, 정규분포를 따를 때 가장 강력한 검정이다. 하지만 정규성에 매우 민감하여 실무에서는 잘 사용되지 않는다.
예제: Bartlett 검정
from scipy.stats import bartlett# Bartlett 검정stat, p_value = bartlett(*groups)print("\n=== Bartlett Test ===")print(f"검정 통계량(T): {stat:.4f}")print(f"p-value: {p_value:.4f}")print(f"\n유의수준 0.05 기준: ", end="")if p_value >0.05:print("등분산성 가정 가능")else:print("등분산성 위배")print("\n⚠️ 주의: Bartlett 검정은 정규성에 민감함")print(" 정규성이 위배되면 잘못된 결과 (과도한 기각)")
=== Bartlett Test ===
검정 통계량(T): 5.6920
p-value: 0.0581
유의수준 0.05 기준: 등분산성 가정 가능
⚠️ 주의: Bartlett 검정은 정규성에 민감함
정규성이 위배되면 잘못된 결과 (과도한 기각)
13.5.4 Fligner-Killeen 검정
Fligner-Killeen 검정은 순위 기반 비모수 검정으로, 극심한 비정규 분포나 두꺼운 꼬리를 가진 분포에서도 안정적이다.
예제: Fligner-Killeen 검정
from scipy.stats import fligner# Fligner-Killeen 검정stat, p_value = fligner(*groups)print("\n=== Fligner-Killeen Test ===")print(f"검정 통계량(H): {stat:.4f}")print(f"p-value: {p_value:.4f}")print(f"\n유의수준 0.05 기준: ", end="")if p_value >0.05:print("등분산성 가정 가능")else:print("등분산성 위배")print("\n✓ 장점: 비모수, 매우 강건")print(" 단점: 검정력이 다소 낮음")
=== Fligner-Killeen Test ===
검정 통계량(H): 9.2507
p-value: 0.0098
유의수준 0.05 기준: 등분산성 위배
✓ 장점: 비모수, 매우 강건
단점: 검정력이 다소 낮음
=== 등분산 검정 결과 요약 ===
Test Statistic p-value Result
Levene 5.1349 0.0064 이분산
Levene (median) 5.1349 0.0064 이분산
Bartlett 5.6920 0.0581 등분산
Fligner-Killeen 9.2507 0.0098 이분산
13.6 등분산성이 위배될 때의 대응 전략
등분산성 검정 결과가 유의하게 이분산이라면, 다음 전략 중 하나를 선택한다.
13.6.1 전략 1: 이분산 허용 검정 사용
등분산 가정을 필요로 하지 않는 대안 검정을 사용한다.
대안 검정
원래 검정
등분산 가정
대안 검정
등분산 불필요
Student t-test
필요
Welch t-test
불필요
One-way ANOVA
필요
Welch ANOVA
불필요
상관 분석
-
비모수 상관 (Spearman)
불필요
회귀 분석
필요
가중 최소제곱(WLS)
이분산 고려
예제: Student t-test vs Welch t-test
from scipy.stats import ttest_ind# 두 종 선택adelie = df[df["species"] =="Adelie"]["body_mass_g"].dropna()gentoo = df[df["species"] =="Gentoo"]["body_mass_g"].dropna()# Student t-test (등분산 가정)t_equal, p_equal = ttest_ind(adelie, gentoo, equal_var=True)# Welch t-test (이분산 허용)t_welch, p_welch = ttest_ind(adelie, gentoo, equal_var=False)print("=== t-test 비교: Adelie vs Gentoo ===")print(f"\nStudent t-test (등분산 가정):")print(f" t = {t_equal:.4f}, p = {p_equal:.4f}")print(f"\nWelch t-test (이분산 허용):")print(f" t = {t_welch:.4f}, p = {p_welch:.4f}")print("\n→ 이분산인 경우 Welch t-test 사용 권장")
=== t-test 비교: Adelie vs Gentoo ===
Student t-test (등분산 가정):
t = -23.4668, p = 0.0000
Welch t-test (이분산 허용):
t = -23.2539, p = 0.0000
→ 이분산인 경우 Welch t-test 사용 권장
13.6.2 전략 2: 분포 변환
데이터를 변환하여 등분산성을 개선할 수 있다.
예제: 로그 변환 후 등분산 검정
# 로그 변환df_log = df.copy()df_log["log_body_mass"] = np.log(df["body_mass_g"])# 변환 후 집단 데이터groups_log = [ df_log[df_log["species"] == sp]["log_body_mass"].dropna()for sp in df_log["species"].unique()]# 변환 전후 Levene 검정 비교stat_orig, p_orig = levene(*groups)stat_log, p_log = levene(*groups_log)print("=== 변환 전후 Levene 검정 비교 ===")print(f"원본 데이터: W = {stat_orig:.4f}, p = {p_orig:.4f}")print(f"로그 변환: W = {stat_log:.4f}, p = {p_log:.4f}")# 시각화fig, axes = plt.subplots(1, 2, figsize=(14, 5))sns.boxplot(x="species", y="body_mass_g", data=df, ax=axes[0])axes[0].set_title("Original Data")sns.boxplot(x="species", y="log_body_mass", data=df_log, ax=axes[1])axes[1].set_title("Log Transformed Data")plt.tight_layout()plt.show()
=== 변환 전후 Levene 검정 비교 ===
원본 데이터: W = 5.1349, p = 0.0064
로그 변환: W = 4.1210, p = 0.0171
주요 변환 방법
로그 변환: 양의 왜도를 줄이고 분산 안정화
제곱근 변환: 로그보다 약한 변환
Box-Cox 변환: 최적의 변환 파라미터 자동 추정
Yeo-Johnson 변환: 0과 음수 포함 데이터 가능
13.6.3 전략 3: 비모수 검정 사용
분포 가정을 하지 않는 비모수 검정을 사용한다.
예제: ANOVA vs Kruskal-Wallis
from scipy.stats import f_oneway, kruskal# 종별 체중 데이터species_groups = [ df[df["species"] == sp]["body_mass_g"].dropna()for sp in df["species"].unique()]# 모수 검정 (ANOVA)f_stat, p_anova = f_oneway(*species_groups)# 비모수 검정 (Kruskal-Wallis)h_stat, p_kw = kruskal(*species_groups)print("=== 다집단 비교: 모수 vs 비모수 ===")print(f"\nOne-way ANOVA (등분산 가정):")print(f" F = {f_stat:.4f}, p = {p_anova:.4f}")print(f"\nKruskal-Wallis (비모수):")print(f" H = {h_stat:.4f}, p = {p_kw:.4f}")print("\n→ 등분산성 위배 시 Kruskal-Wallis 사용")
=== 다집단 비교: 모수 vs 비모수 ===
One-way ANOVA (등분산 가정):
F = 341.8949, p = 0.0000
Kruskal-Wallis (비모수):
H = 212.0851, p = 0.0000
→ 등분산성 위배 시 Kruskal-Wallis 사용
13.6.4 전략 4: 가중 회귀 (회귀분석)
회귀분석에서 이분산성이 있을 때 가중 최소제곱(Weighted Least Squares)을 사용한다.
print("=== 정규성 및 등분산성 검정 종합 ===\n")# 각 종별 정규성 검정for species in df["species"].unique(): data = df[df["species"] == species]["body_mass_g"].dropna() stat, p_val = stats.shapiro(data)print(f"{species} 정규성: W = {stat:.4f}, p = {p_val:.4f} ", end="")print("→ 정규"if p_val >0.05else"→ 비정규")# 등분산성 검정stat, p_val = levene(*groups)print(f"\n등분산성 (Levene): W = {stat:.4f}, p = {p_val:.4f} ", end="")print("→ 등분산"if p_val >0.05else"→ 이분산")# 최종 권장print("\n=== 최종 권장 검정 ===")ifall([stats.shapiro(df[df["species"] == sp]["body_mass_g"].dropna())[1] >0.05for sp in df["species"].unique()]) and p_val >0.05:print("✓ Student t-test / ANOVA 사용 가능")elif p_val >0.05:print("△ 정규성 위배 → 비모수 검정 또는 변환 후 검정")else:print("✓ 이분산 → Welch t-test / Welch ANOVA 권장")
=== 정규성 및 등분산성 검정 종합 ===
Adelie 정규성: W = 0.9812, p = 0.0423 → 비정규
Chinstrap 정규성: W = 0.9845, p = 0.5605 → 정규
Gentoo 정규성: W = 0.9861, p = 0.2605 → 정규
등분산성 (Levene): W = 5.1349, p = 0.0064 → 이분산
=== 최종 권장 검정 ===
✓ 이분산 → Welch t-test / Welch ANOVA 권장
13.8 요약
이 장에서는 등분산 검정의 개념, 방법, 그리고 이분산 시 대응 전략을 학습했다. 주요 내용은 다음과 같다.
등분산 검정 방법 요약
방법
유형
장점
단점
권장 상황
박스플롯
시각적
직관적, 이상치 확인
주관적
초기 탐색
잔차 플롯
시각적
회귀 이분산 확인
회귀 전용
회귀분석
Levene
통계적
안정적, 널리 사용
보통 검정력
일반적 상황 (권장)
Bartlett
통계적
검정력 높음
정규성 민감
정규분포 확실 시
Fligner-Killeen
통계적
매우 강건
검정력 낮음
극심한 비정규
이분산 시 대응 전략
전략
방법
장점
단점
적용 상황
대안 검정
Welch t-test, Welch ANOVA
변환 불필요
검정력 약간 낮음
첫 번째 선택
분포 변환
로그, Box-Cox
등분산성 개선
해석 복잡
변환이 합리적인 경우
비모수 검정
Mann-Whitney, Kruskal-Wallis
분포 가정 불필요
검정력 낮음
정규성도 위배
가중 회귀
WLS
효율적 추정
구현 복잡
회귀분석
실무 점검 프로세스
시각적 확인: 박스플롯으로 분산 차이 확인
집단별 분산 계산: 최대/최소 비율 확인 (2배 이상 주의)
통계적 검정: Levene 검정 수행
정규성 고려: 정규성도 함께 확인
대응 전략 선택:
등분산 O → Student t-test, ANOVA
등분산 X → Welch 검정 또는 비모수 검정
주요 주의사항
정규성보다 등분산성 위반이 더 심각할 수 있음
Bartlett는 정규성에 민감하므로 실무에서 비권장
Levene이 가장 안정적이고 널리 사용됨
표본 크기가 집단 간 불균형하면 이분산성 영향 증가
시각적 확인과 통계적 검정을 함께 고려
등분산 검정은 집단 간 비교 분석의 필수 단계이다. 시각적 방법과 통계적 검정을 종합적으로 활용하고, 이분산성이 확인되면 적절한 대안 검정이나 변환을 사용하는 것이 중요하다. 다음 장에서는 등분산성 가정을 바탕으로 한 t-검정과 ANOVA를 학습할 것이다.